网络爬虫是一种自动获取网页内容的程序。在Python中,我们可以使用requests库来发送HTTP请求,并使用lxml库来解析HTML文档并提取所需的数据。
一、HTML
HTML是构建网页的标准标记语言,它使用一系列标签(tag)来定义网页内容的结构和格式。以下是一些关于HTML的基本知识点,以及如何利用Python进行网络爬虫的概述:
1. HTML基础
- 标签(Tags):HTML使用成对的标签来包围内容,例如
<title>和</title>。 - 元素(Elements):标签及其包含的内容构成HTML元素。
- 属性(Attributes):标签可以拥有属性,提供关于元素的额外信息,例如
<a href="https://example.com">中的href。 - Body和Header:HTML文档分为
<body>部分(显示在浏览器中的内容)和<head>部分 - 嵌套:HTML标签可以嵌套,但必须正确关闭。
- 注释:HTML注释使用
<!-- 注释内容 -->。
2.代码结构
以下是一个简单的HTML代码结构示例:
<!DOCTYPE html>
<html lang="zh">
<head>
<meta charset="UTF-8">
<title>网页标题</title>
</head>
<body>
<h1>一级标题</h1>
<p>这是一个段落。</p>
<a href="https://www.example.com">链接到外部网站</a>
<img src="image.jpg" alt="图片描述">
</body>
</html>
在这个示例中,我们可以看到以下主要部分:
<!DOCTYPE html>:声明文档类型为HTML5。<html>:HTML文档的根元素。<head>:包含元信息,如字符集、标题等。<meta charset="UTF-8">:指定文档使用的字符编码。<title>:定义网页的标题,显示在浏览器的标题栏或标签页上。<body>:包含网页的所有可见内容,如文本、图像、链接等。<h1>:定义一个一级标题。<p>:定义一个段落。<a href="https://www.example.com">:创建一个指向外部网站的链接。<img src="image.jpg" alt="图片描述">:插入一张图片,并提供替代文本(当图片无法显示时)。
这只是HTML的基本结构,实际上还有更多的标签和属性可以用来创建更复杂的网页布局和功能。
3.注意事项
要确保解析时考虑到不同网站的HTML结构差异,最好可以增加异常处理逻辑以应对网络请求错误、解析错误等。注意要遵守网站的robots.txt规则,这是网站告诉爬虫哪些页面可以抓取的协议。另外,不要频繁请求一个网站,可能会被封IP,一般解决这个问题,我们会利用time库,在爬取一页数据后,对程序进行休眠。
二、XPath
在使用Python进行网络爬虫时,XPath(XML Path Language)是一种在XML文档中查找信息的语言,也可以用于HTML文档。XPath可以用来选取HTML元素,指定元素的属性或者文本等内容。
1. XPath语法基础:
- /:从根节点选取
- //:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置
- .:选取当前节点
- ..:选取当前节点的父节点
- @:选取属性
2. 使用Python的lxml库来解析HTML文档并使用XPath提取数据(一般情况下简单的举例):
from lxml import etree
html = '''
<html>
<head>
<title>Example Page</title>
</head>
<body>
<div id="content">
<ul class="list">
<li class="item">Item 1</li>
<li class="item">Item 2</li>
<li class="item">Item 3</li>
</ul>
</div>
</body>
</html>
'''
解析HTML文档,使用XPath提取数据
html_element = etree.HTML(html)
title = html_element.xpath('//title/text()')[0]
content_div = html_element.xpath('//div[@id="content"]')[0]
item_list = html_element.xpath('//ul[@class="list"]/li')
item_texts = [li.text for li in item_list]
print("Title:", title)
print("Content Div:", etree.tostring(content_div).decode())
print("Item Texts:", item_texts)
3.更多XPath表达式示例(下列主要是在复制后的xpath路径加上的后缀及后缀含义):
下列只是一般情况的举例,具体实例要具体分析。
- //tag:选取所有名为tag的元素
- //tag[@attribute]:选取所有具有名为attribute的属性的tag元素
- //tag[contains(@attribute, 'value')]:选取所有属性attribute包含'value'的tag元素
- //tag[position()=1]:选取第一个tag元素
- //tag[last()]:选取最后一个tag元素
- //parenttag/childtag:选取所有parenttag元素的直接childtag子元素
4. 注意事项:
在网络爬虫中,由于HTML文档结构的复杂性,可能需要组合多个XPath表达式来准确地选取所需数据,而且XPath表达式是大小写敏感的,因此需要注意大小写。
总的来说,使用XPath进行网络爬虫时,需要熟悉XPath的语法和表达式,以便精确地选取所需的HTML元素和数据。通过结合Python的lxml库,可以有效地解析HTML文档并提取出有价值的信息。
三、实例
接下来,将利用xpath来爬取壁纸,选取的实例是bilibili中专栏文章里的一篇关于紫罗兰永恒花园的文章进行爬取(另外,在这里小编感谢一下齐尧友情提供的网址),我们将总共爬取32张照片。
1.安装所需库:
编程工具:IDLE (Python 3.12 64-bit)
对于py文件,一般建议保存在一个文件夹里,这样通过文件处理方法,就能将例如txt文件或者jpg文件默认保存在该文件夹里。
因为我们接下来主要使用的第三方库是requests库和lxml库,所以我们应该在cmd中安装所需库:
pip install requests
pip install lxml
2.导入所需库
import requests
from lxml import etree
3.发送HTTP请求并获取网页内容
url="https://www.bilibili.com/read/cv5055394/"
header={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46"}
re=requests.get(url=url,headers=header)
re.encoding=re.apparent_encoding
在这段代码中,header中字典的元素为UA伪装,主要是为了让网页允许程序进行访问。另外,对于”User-Agent”的获取,将在第五点中进行说明。 对于第五段代码,主要是将HTML文档的格式进行规范统一,以避免出现乱码。
4.使用lxml解析HTML文档
tree=etree.HTML(re.text)
5.获取Xpath路径:
这里小编用的是edge浏览器,不同浏览器虽然页面显示有略微的不同,但基本上所以要素都是完备的。
首先,打开你要爬取内容的网站,这里的实例就是"https://www.bilibili.com/read/cv5055394/ ", 之后,在空白区域,鼠标右击,在点击“检查”(一般情况下,浏览器会有默认快捷键F12,也是打开检查页面),之后,会显示如下的界面:
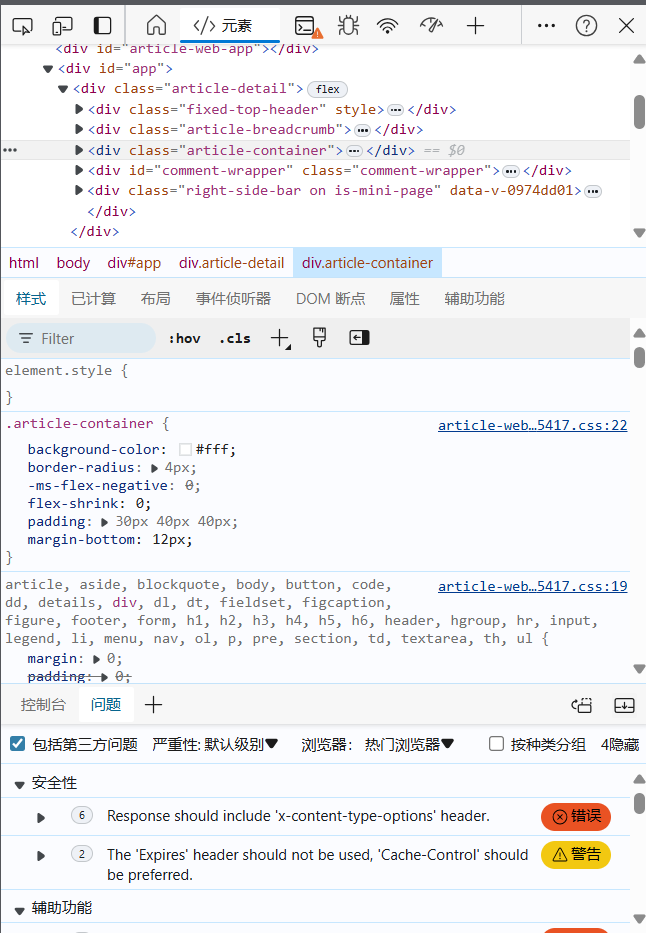
这就是一张关于HTML代码的截图。 在之后,点击该区域的右上角,即下示状态栏的最左的那一个图标:

之后,点击第一张照片,该区域会变化成下示内容:
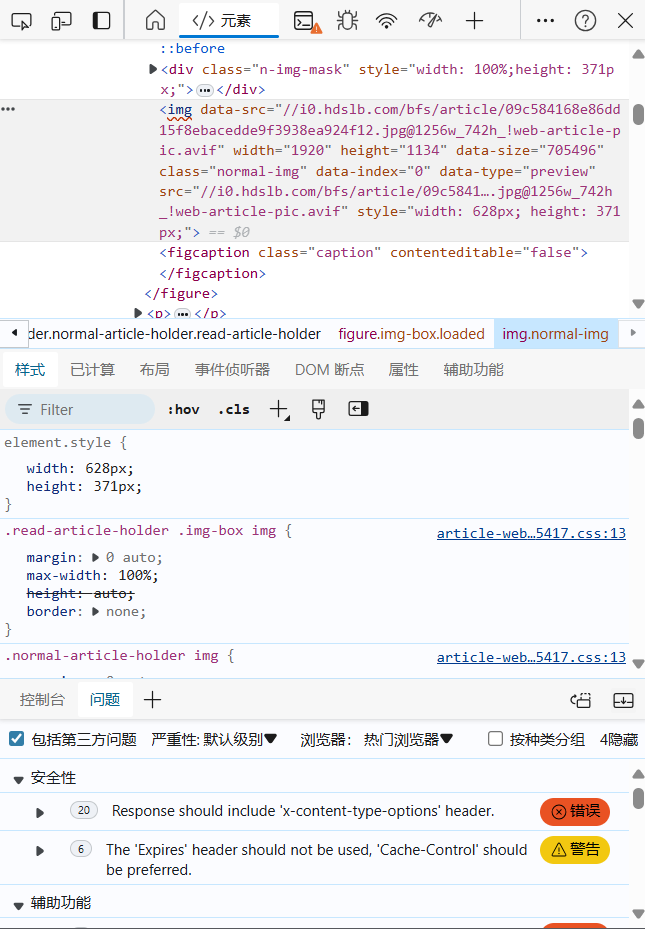
再在中间html代码显示出的阴影部分,右键将鼠标滑至复制选项,
再选择复制Xpath,这样你就得到了第一张照片的Xpath路径:
'//[@id="read-article-holder"]/figure[1]/img'。
另外,因为我们是要爬取多张照片,再按照上述内容获取第32张照片的Xpath路径:
'//[@id="read-article-holder"]/figure[32]/img'。
两相对比,发现只有figure[]中的数字发生改变,因此,我们可以用for循环和字符串的方法,来对Xpath路径进行修改。详细代码于第六点展示。
最后,对于”User-Agent”的获取,在状态栏里点击 ,之后再刷新一下页面或者ctrl+R,再将下示的内容,利用鼠标,将其滑动到最上面:
,之后再刷新一下页面或者ctrl+R,再将下示的内容,利用鼠标,将其滑动到最上面:
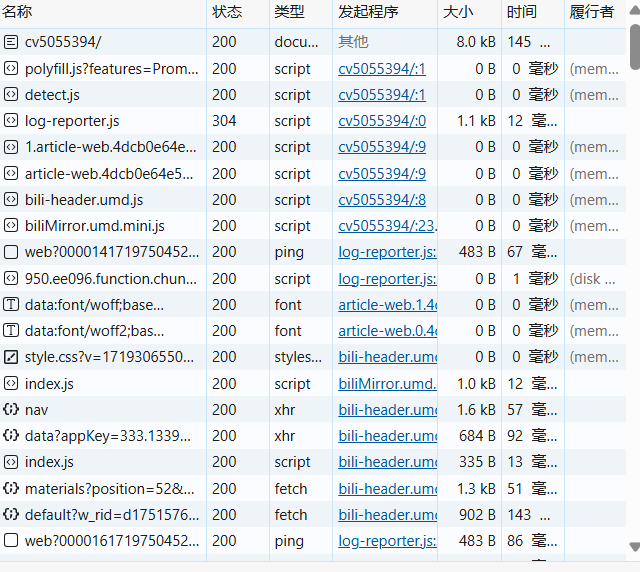
点击第一个,会出现下示:
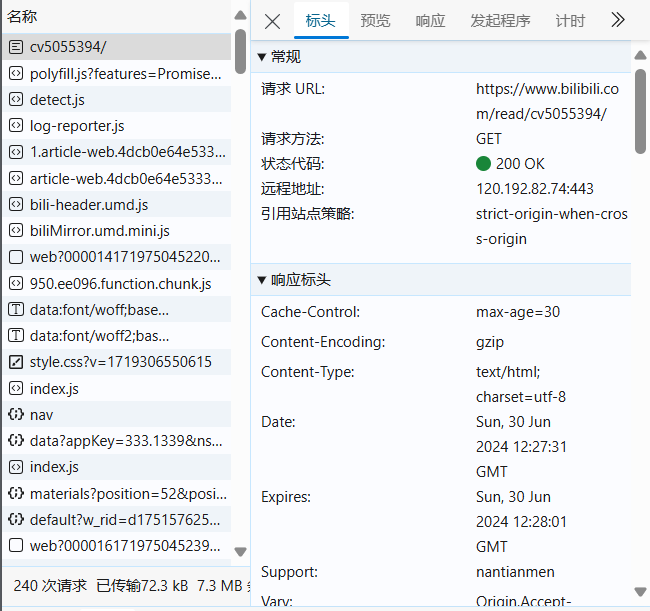
右侧第一行中的url就是该网站的网址,第二行的GET指的是直接访问。对于header,中文翻译为表头,之后再下滑到最后,就会出现”User-Agent”的内容。
6.使用XPath提取数据:
一般利用tree.xpath( )方法进行提取,括号里为Xpath路径,另外该方法得到的一般结果为列表,我们想要利用的为第一个元素,所以写成该格式:img_url=tree.xpath('Xpath路径)[0]。 又由于我们要爬取的为图片,HTML如下:
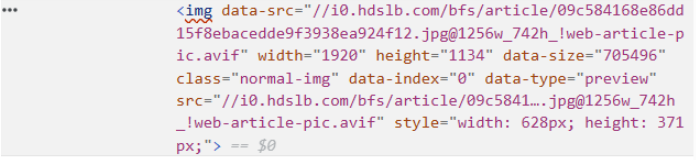
其属性为data-src,所以我们要在Xpath路径后加上’/@data-src’,用来获取该图片的部分网址(即data-src等号后面的引号里面的内容)。又通过data-src的信息显示,为了补全网址格式,所以要有’’img_url='https:'+img_url’’,这样我们就得到了这张照片的网址,之后再通过requests库和文件处理方法,就能直接保存该照片。 因为我们是要爬取32张照片,所以要用for循环,和字符串中的format()方法来进行转化和将每张照片编上序号,之后再通过文件管理将爬取的图片进行保存。
所以该部分代码如下:
for page in range(1,33):
img_url=tree.xpath('//*[@id="read-article-holder"]/figure[{}]/img/@data-src'.format(page)[0]
img_url='https:'+img_url
res=requests.get(url=img_url,headers=header)
with open("{}.jpg".format(page),"wb") as f:
f.write(res.content)
7.完整代码
另外,这段代码又加入了try...except语句,用来增加异常处理逻辑,便于在修改代码时,能够准确知道错误出现的地方。
import requests
from lxml import etree
def get_html(url,header):
try:
re = requests.get(url=url,headers=header)
re.raise_for_status()
re.encoding = re.apparent_encoding
return re.text
except requests.RequestException as e:
print("请求错误:", e)
except requests.HTTPError as e:
print("HTTP错误:", e)
except requests.ConnectionError as e:
print("连接错误:", e)
except requests.Timeout as e:
print("超时错误:", e)
return None
def parse_html(html):
try:
tree = etree.HTML(html)
for page in range(1,33):
img_url=tree.xpath('//*[@id="read-article-holder"]/figure[{}]/img/@data-src'.format(page))[0]
img_url='https:'+img_url
res=requests.get(url=img_url,headers=header)
with open("{}.jpg".format(page),"wb") as f:
f.write(res.content)
except Exception as e:
print("解析错误:", e)
return None
if __name__ == "__main__":
url="https://www.bilibili.com/read/cv5055394/"
header={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36 Edg/118.0.2088.46"}
html = get_html(url,header)
if html:
parse_html(html)
还需特别注意是在实际使用时,需要根据目标网站的结构进行调整XPath。同时,网络爬虫可能会受到反爬机制的影响,需要遵守网站的robots.txt规则,合理设置请求时间间隔等。
免责声明
技术交流目的
本文旨在提供一个关于网络爬虫技术的交流平台,通过分享基础知识、实践经验、技术难点及解决方案等内容,促进同行之间的学习与合作。所有内容均基于作者个人见解及实验成果,旨在促进技术知识的传播与共享。
合法合规使用
在使用本文介绍的网络爬虫技术时,请严格遵守相关法律法规及目标网站的robots.txt协议。我们强烈反对并谴责任何利用爬虫技术进行非法数据抓取、侵犯用户隐私、破坏网站服务等行为。请确保您的爬虫行为合法、合规,并尊重目标网站的权益。
责任与风险
本文提供的信息仅供参考,不构成任何形式的法律建议或操作指南。因使用本文内容而产生的任何法律后果、技术风险或数据安全问题,均由使用者自行承担。作者及所属平台不承担任何直接或间接的责任。
更新与准确性
网络爬虫技术及其相关法律法规处于不断发展和变化之中。本文内容可能随时间推移而变得过时或不再适用。作者将尽力保持文章的更新与准确性,但无法承诺所有信息的绝对准确或完整性。读者在使用前请自行核实相关信息的最新状态。

